Appearance
In Steve Yegge's 8 stages of dev evolution to AI I am presently in Stage 2.
Stage 2: Coding agent in IDE, permissions turned on. A narrow coding agent in a sidebar asks your permission to run tools.
I don't have a problem with this, nor any particular desire to reach a higher stage. What I do have is a vendetta against techfluencers claiming agentic coding has 1000xd their throughput without bringing the receipts.

Tens of thousands of lines of code is not a success metric. A monkey can write tens of thousands of lines of code and open apps.
What did AI actually do? How much time did it take? How much human time did it save? What did it cost? Questions that always seem to go unanswered.
Instead of fuming in silence, I installed Claude Code on a DGX Spark, memorized some tmux commands (which should win an award for most unintuitive CLI commands), and began documenting my own answers.
The problem
In exchange for a name and URL, Diffbot's Enhance API will return the closest Organization or Person record match from the Knowledge Graph. Its cousin, Bulk Enhance API can do this for hundreds of thousands of records. This is more commonly known in the industry as "enrichment". Though, we prefer the film industry term:
Setting up and exporting a Bulk Enhance as an API request can be a bit involved. Many users opt to use the Diffbot Dashboard UI for one-off enhance tasks. The workflow is simple — upload a CSV of inputs (name, URL, etc.), wait for the bulk enhance to complete, export the enhanced records as a CSV.
This works well for jobs in the thousands of records, but starts to reveal a failure mode when tens of thousands of records are exported. Because the data is natively structured as JSON, a CSV export will require a transformation step on the server side. This transformation process usually takes a few ignorable seconds, but could extend into a few minutes for larger exports, which is an unacceptable amount of time for a user to wait for something to happen.
Worse still, if the transformation takes more than 2 minutes, Bulk Enhance API returns a JSON status response. Presumably to avoid timing out the client, but results in a very confused end user.
If that all made sense to you, great! Because my first version describing this issue to Claude Code caused it to generate a solution plan that made absolutely no sense. The second version, in retrospect, wasn't much better. But I wasn't feeling particularly retrospective at the time and sent it to Claude Code anyway. I've included the full prompt from the second version below.
### Issue
The Bulk Enhance CSV designer view (/enhance/bulk/csv/) "fails" on very large exports of 30k+ records. "Failure" in this case is a very long stall time before the Bulk Enhance API finally returns a status JSON as a fallback when a timeout is reached. This appears to be a failure state to the user because no export was generated.
What's actually happening is that the Bulk Enhance API returned a status JSON response when the export failed to generate within a 2 min timeout. The status JSON does include some details on the status of the export, but it is not very readable to the user. When the export is ready, the original endpoint can be requested again and the export download will begin immediately.
### Proposed Solution
1. Instead of having the user wait for 2 mins for a status JSON on large exports, we'll use a param (`wait=5`) that will tell the Bulk Enhance API to wait a maximum of 5 seconds for an export before falling back to a status JSON response.
2. A modal should appear immediately after a CSV export is requested by the user notifying them that an export is being generated.
3. If a status JSON response is returned, wait 5 more seconds and poll the same endpoint. If it returns a status JSON response again, repeat the polling again after 5 seconds.
4. Continue polling until a CSV export is returned from the request, after which the modal should be updated to say something akin to "Download Started..." with a link to manually request the same endpoint again in case it did not start on its own.Claude Code takes the wheel
This issue as written would fail the first round of an associate product manager interview, but Claude Code doesn't care. Its new plan passes muster and with my approval gets to work immediately.
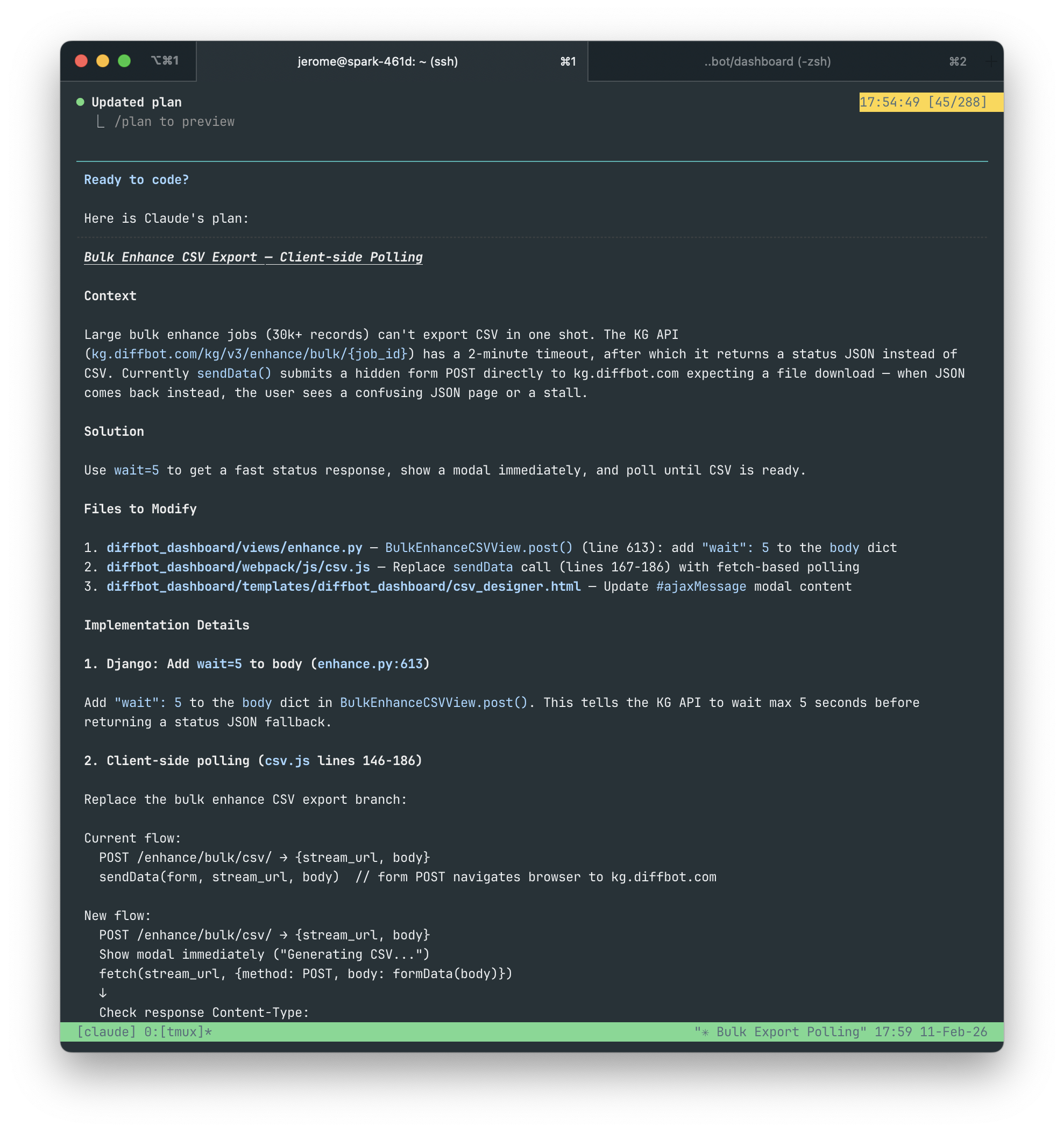
Claude says it's done. I ask it to start the dev server so I can test it. Claude tells me to access the app with localhost:8000. I'm not connected directly to the Spark sandbox, so I access it using its local address (spark:8000), which doesn't resolve. My
I ask Claude to add spark to hosts. It figures out what I mean by this and adds the spark to ALLOWED_HOSTS in my .env.dev file. As expected, the address still won't resolve. .env.dev is a shared boilerplate .env file that isn't actually used by the dev server. I ask Claude to edit my local .env file instead. spark:8000 resolves!
The excitement doesn't last long. I am unable to login to the app. I paste the error from the browser console directly to Claude:
CSRF verification failedClaude adds spark to the list of CSRF_TRUSTED_ORIGINS in my local .env file. Makes sense.
I try logging in again. User not found. That's right, I need to create a super user for this fresh build. I do this manually. Djano’s user CLI wizard is pretty straight forward. I don't need Claude to fill out a form for me.
Login works! I need to add my Diffbot API token to this user before I can test the fix. I head on to django's user admin to find my next boss fight.
AttributeError ‘super’ object has no attribute ‘dicts’ in Django Admin for custom User ModelI paste this into Claude. Claude notes that this is an issue with Python3.14, which django 4.2 doesn't support. It then proceeds to patch a method in the django library.
Whoa there! 😱
I exit Claude.
Claude's decisions are starting to annoy me. And besides, this is a pretty easy fix. I delete the /env folder and initiate a fresh virtual environment using python3.12, which is supported by django 4.2.
bash
python3.12 -m venv env
source env/bin/activate
pip install -r requirements.txtAfter resolving an issue with building libsass, the rest of the install went fine.
Resuming my previous session with Claude Code, I tell it to note in a CLAUDE.md file to always source env and use python3. I also tell Claude to add a note to our local development README about using python3.12.
I tell Claude to restart the dev server. Login works. User admin works. I can finally test the fix.
Testing the vibe coded fix
The feature works exactly as described. No notes. Almost disappointingly uneventful.
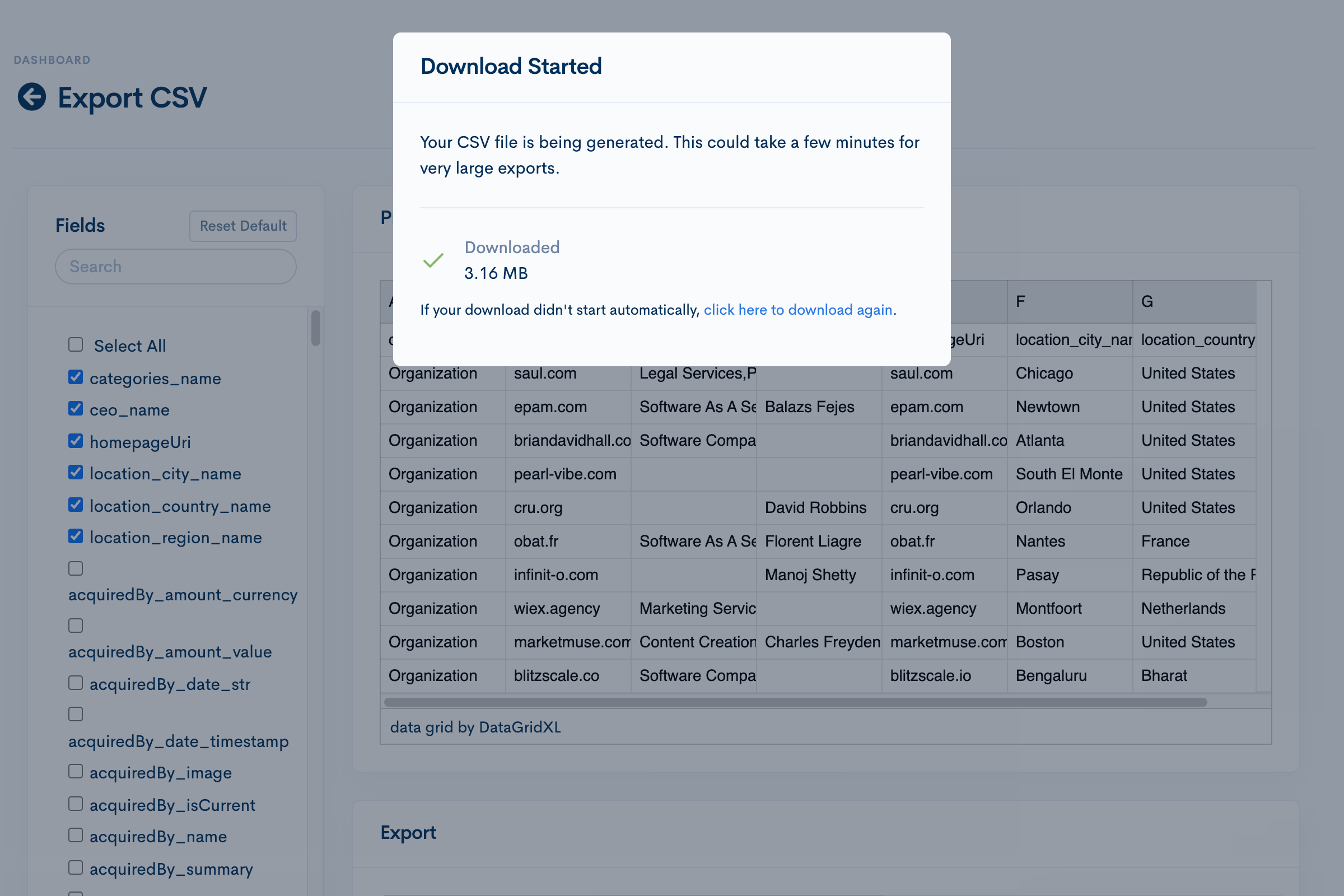
I offer Claude some tweaks.
Most of the time spent isn't waiting for the download to finish, it's waiting for the download to start. Let's kill the "bytes loader" and shoot for a more async modal message. Also, let's send the user an email when the export is complete in case the download didn't start for any reason.Claude comes up with a plan. Looks good. It churns away for a few minutes and it's done.
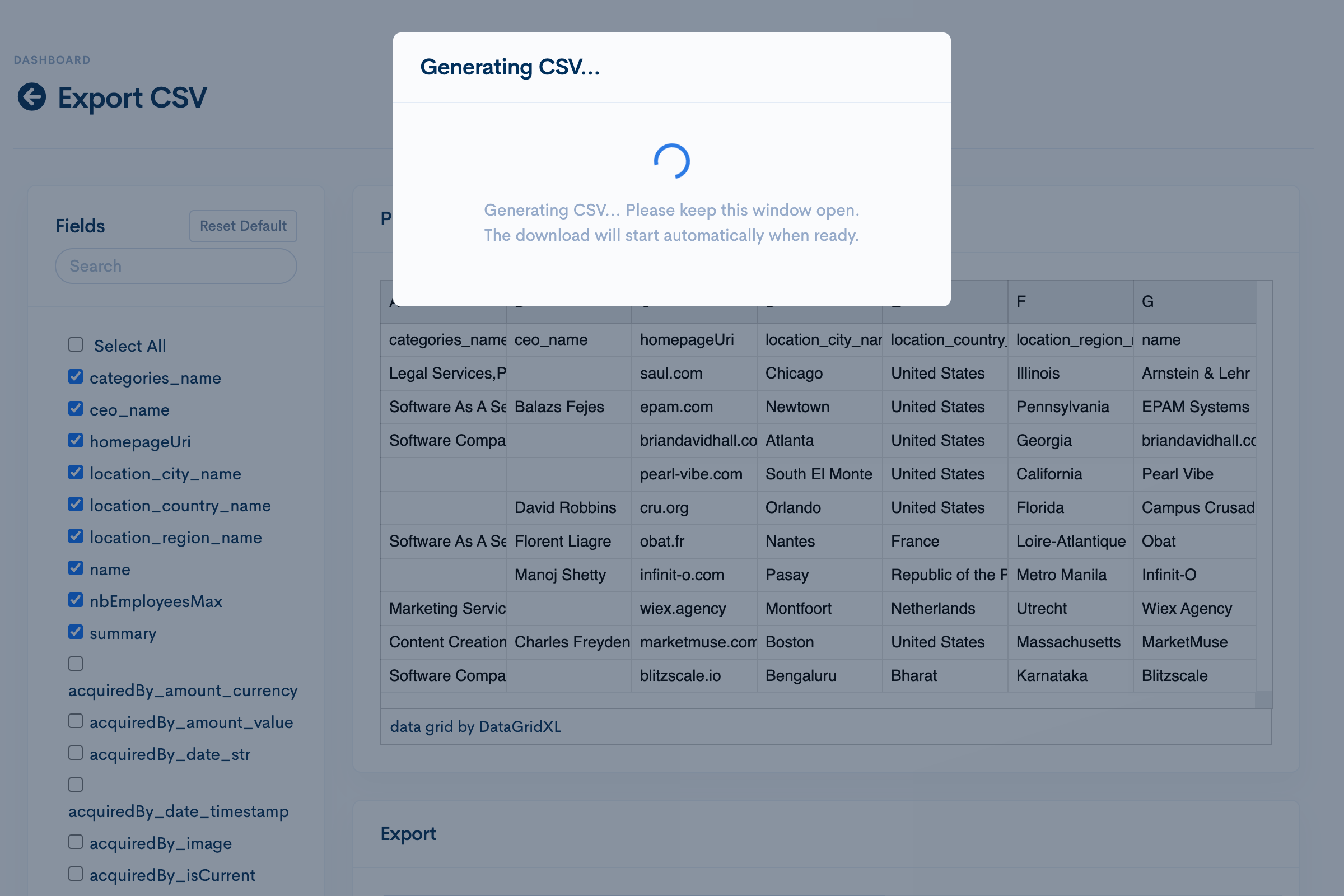
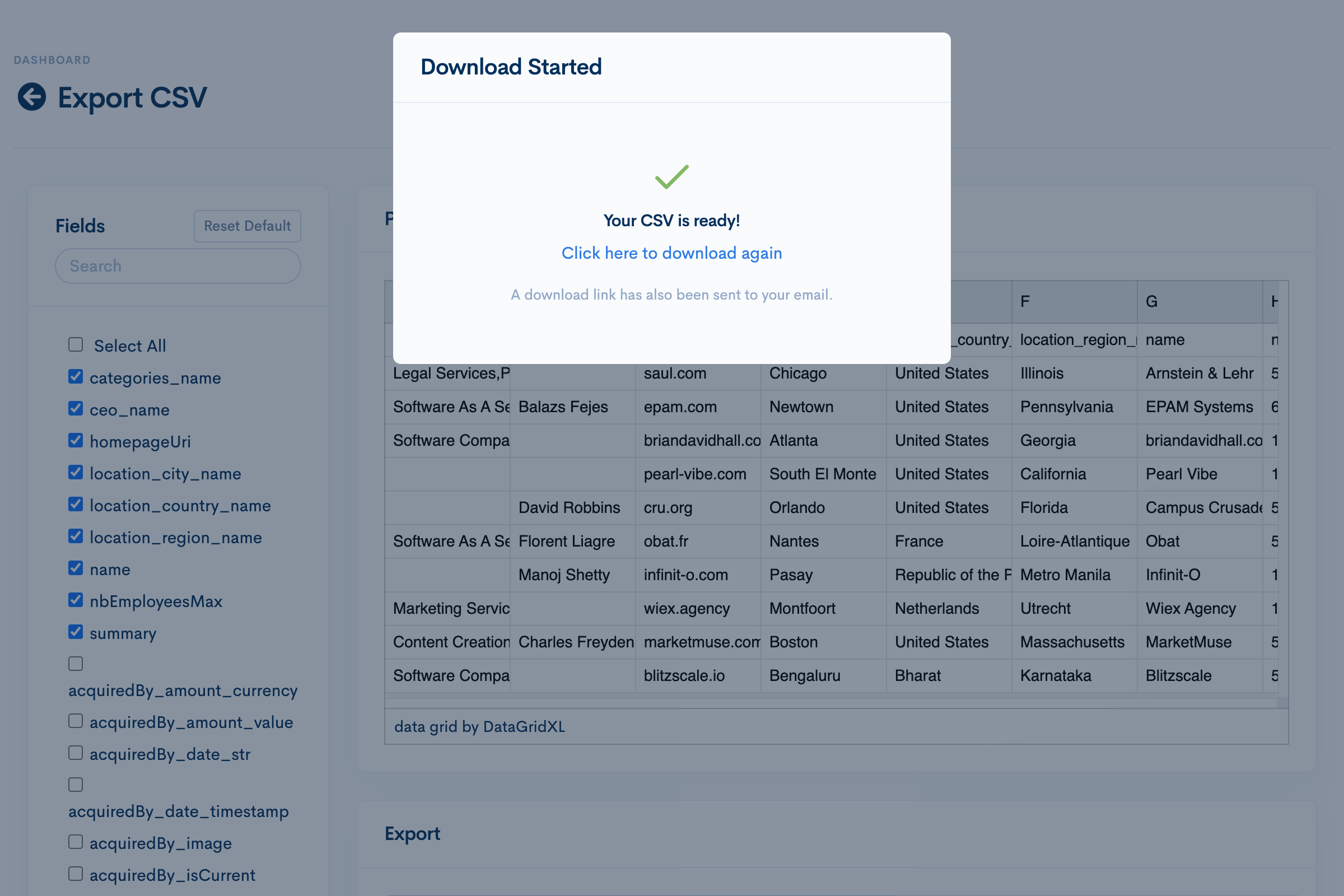
I start a remote session on VSC to review the final code changes, make some light copy tweaks, then commit and push an MR.
Stats
Token usage stats and cost compiled using npx ccusage.
- Days Working on Task: 2
- AI Dev Evolution Stage: 5
- Total Input Tokens: 4,482
- Total Output tokens: 7,421
- Total Tokens (including cache): 16,124,485
- Total API Cost: $10.71
Notes
- Stage 2 to 5 looks like a big skip, but it really wasn’t. It didn’t make sense to YOLO mode on an IDE remoted into my sandbox. That would mean being stuck with GitHub Copilot and no way to check in on Claude Code while I’m on the toilet.
- I’m on Claude Pro, so the API cost doesn’t apply but I kept it for completeness.
- I never ran into the 5 hour token limit on the Claude Pro plan in this project.
Vibes
Learning pains aside, the vibes were good. I feel pretty confident round 2 should be a lot easier. Maybe even faster. Claude Code should be able to one-shot future tasks of this caliber. A happy place I'd like to be in is an autonomous setup initiated from being assigned an issue on Gitlab.
See you on Vibe Log #2.